[Top] [Prev] [Next]
3.11 Chunked (or Tiled) Scientific Data Sets
NOTE: It is strongly encouraged that HDF users who wish to use the SD chunking routines first read the section on SD chunking in Chapter 14, HDF Performance Issues. In that section the concepts of chunking are explained, as well as their use in relation to HDF. As the ability to work with chunked data has been added to HDF functionality for the purpose of addressing specific performance-related issues, you should first have the necessary background knowledge to correctly determine how chunking will positively or adversely affect your application.
This section will refer to both "tiled" and "chunked" SDSs as simply chunked SDSs, as tiled SDSs are the two-dimensional case of chunked SDSs.
3.11.1 Making an SDS a Chunked SDS: SDsetchunk
In HDF, an SDS must first be created as a generic SDS through the SDcreate routine, then SDsetchunk is called to make that generic SDS a chunked SDS. Note that there are two restrictions that apply to chunked SDSs. The maximum number of chunks in a single HDF file is 65,535 and a chunked SDS cannot contain an unlimited dimension. SDsetchunk sets the chunk size and the compression method for a data set. The syntax of SDsetchunk is as follows:
C: status = SDsetchunk(sds_id, c_def, flag);
FORTRAN: status = sfschnk(sds_id, dim_length, comp_type, comp_prm)
The chunking information is provided in the parameters c_def and flag in C, and the parameters comp_type and comp_prm in FORTRAN-77.
In C:
The parameter c_def has type HDF_CHUNK_DEF which is defined as follows:
typedef union hdf_chunk_def_u {
int32 chunk_lengths[MAX_VAR_DIMS];
struct {
int32 chunk_lengths[MAX_VAR_DIMS];
int32 comp_type;
comp_info cinfo;
} comp;
struct {
int32 chunk_lengths[MAX_VAR_DIMS];
intn start_bit;
intn bit_len;
intn sign_ext;
intn fill_one;
} nbit;
} HDF_CHUNK_DEF
Refer to the reference manual page for SDsetcompress for the definition of the structure comp_info.
The parameter flag specifies the type of the data set, i.e., if the data set is chunked or chunked and compressed with either RLE, Skipping Huffman, GZIP, or NBIT compression methods. Valid values of flag are HDF_CHUNK for a chunked data set, (HDF_CHUNK | HDF_COMP) for a chunked data set compressed with RLE, Skipping Huffman, and GZIP compression methods, and (HDF_CHUNK | HDF_NBIT) for a chunked NBIT-compressed data set.
There are three pieces of chunking and compression information which should be specified: chunking dimensions, compression type, and, if needed, compression parameters.
If the data set is chunked, i.e., flag value is HDF_CHUNK, then the elements of the array chunk_lengths in the union c_def (c_def.chunk_lengths[]) have to be initialized to the chunk dimension sizes.
If the data set is chunked and compressed using RLE, Skipping Huffman, or GZIP methods (i.e., flag value is set up to (HDF_CHUNK | HDF_COMP)), then the elements of the array chunk_lengths of the structure comp in the union c_def (c_def.comp.chunk_lengths[]) have to be initialized to the chunk dimension sizes.
If the data set is chunked and NBIT compression is applied (i.e., flag values is set up to (HDF_CHUNK | HDF_NBIT)), then the elements of the array chunk_lengths of the structure nbit in the union c_def (c_def.nbit.chunk_lengths[]) have to be initialized to the chunk dimension sizes.
The values of HDF_CHUNK, HDF_COMP, and HDF_NBIT are defined in the header file hproto.h.
Compression types are passed in the field comp_type of the structure cinfo, which is an element of the structure comp in the union c_def (c_def.comp.cinfo.comp_type). Valid compression types are: COMP_CODE_RLE for RLE, COMP_CODE_SKPHUFF for Skipping Huffman, COMP_CODE_DEFLATE for GZIP compression.
For Skipping Huffman and GZIP compression, parameters are passed in corresponding fields of the structure cinfo. Specify skipping size for Skipping Huffman compression in the field c_def.comp.cinfo.skphuff.skp_size. Specify deflate level for GZIP compression in the field c_def.comp.cinfo.deflate_level. Valid values of deflate levels are integers from 1 to 9 inclusive.
NBIT compression parameters are specified in the fields start_bit, bit_len, sign_ext, and fill_one in the structure nbit of the union c_def.
In FORTRAN-77:
The dim_length array specifies the chunk dimensions.
The comp_type parameter specifies the compression type. Valid compression types and their values are defined in the hdf.inc file, and are listed below.
-
COMP_CODE_NONE (or 0) for uncompressed data
-
COMP_CODE_RLE (or 1) for data compressed using the RLE compression algorithm
-
COMP_CODE_NBIT (or 2) for data compressed using the NBIT compression algorithm
-
COMP_CODE_SKPHUFF (or 3) for data compressed using the Skipping Huffman compression algorithm
-
COMP_CODE_DEFLATE (or 4) for data compressed using the GZIP compression algorithm
The parameter comp_prm(1) specifies the skipping size for the Skipping Huffman compression method and the deflate level for the GZIP compression method.
For NBIT compression, the four elements of the array comp_prm correspond to the four NBIT compression parameters listed in the structure nbit. The array comp_prm should be initialized as follows:
Refer to the description of the union HDF_CHUNK_DEF and of the routine SDsetnbitdataset for NBIT compression parameter definitions.
SDsetchunk returns either a value of SUCCEED (or 0) or FAIL (or -1). Refer to Table 3AA and Table 3AB for the descriptions of the parameters of both versions.
TABLE 3AA - SDsetchunk Parameter List
TABLE 3AB - sfschnk Parameter List
3.11.2 Setting the Maximum Number of Chunks in the Cache: SDsetchunkcache
To maximize the performance of the HDF library routines when working with chunked SDSs, the library maintains a separate area of memory specifically for cached data chunks. SDsetchunkcache sets the maximum number of chunks of the specified SDS that are cached into this segment of memory. The syntax of SDsetchunkcache is as follows:
C: status = SDsetchunkcache(sds_id, maxcache, flag);
FORTRAN: status = sfscchnk(sds_id, maxcache, flag)
When the chunk cache has been filled, any additional chunks written to cache memory are cached according to the Least-Recently-Used (LRU) algorithm. This means that the chunk that has resided in the cache the longest without being reread or rewritten will be written over with the new chunk.
By default, when a generic SDS is made a chunked SDS, the parameter maxcache is set to the number of chunks along the fastest changing dimension. If needed, SDsetchunkcache can then be called again to reset the size of the chunk cache.
Essentially, the value of maxcache cannot be set to a value less than the number of chunks currently cached. If the chunk cache is not full, then the size of the chunk cache is reset to the new value of maxcache only if it is greater than the current number of chunks cached. If the chunk cache has been completely filled with cached data, SDsetchunkcache has already been called, and the value of the parameter maxcache in the current call to SDsetchunkcache is larger than the value of maxcache in the last call to SDsetchunkcache, then the value of maxcache is reset to the new value.
Currently the only allowed value of the parameter flag is 0, which designates default operation. In the near future, the value HDF_CACHEALL will be provided to specify that the entire SDS array is to be cached.
SDsetchunkcache returns the maximum number of chunks that can be cached (the value of the parameter maxcache) if successful and FAIL (or -1) otherwise. The parameters of SDsetchunkcache are further described in Table 3AC.
TABLE 3AC - SDsetchunkcache Parameter List
3.11.3 Writing Data to Chunked SDSs: SDwritechunk and SDwritedata
Both SDwritedata and SDwritechunk can be used to write to a chunked SDS. Later in this chapter, situations where SDwritechunk may be a more appropriate routine than SDwritedata will be discussed, but, for the most part, both routines achieve the same results. SDwritedata is discussed in Section 3.5.1 on page 28. The syntax of SDwritechunk is as follows:
C: status = SDwritechunk(sds_id, origin, datap);
FORTRAN: status = sfwchnk(sds_id, origin, datap)
OR status = sfwcchnk(sds_id, origin, datap)
The location of data in a chunked SDS can be specified in two ways. The first is the standard method used in the routine SDwritedata that access both chunked and non-chunked SDSs; this method refers to the starting location as an offset in elements from the origin of the SDS array itself. The second method is used by the routine SDwritechunk that only access chunked SDSs; this method refers to the origin of the chunk as an offset in chunks from the origin of the chunk array itself. The parameter origin specifies this offset; it also may be considered as chunk's coordinates in the chunk array. Figure 3d on page 66 illustrates this method of chunk indexing in a 4-by-4 element SDS array with 2-by-2 element chunks.
FIGURE 3d - Chunk Indexing as an Offset in Chunks
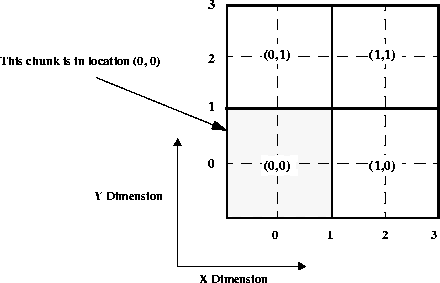
SDwritechunk is used when an entire chunk is to be written and requires the chunk offset to be known. SDwritedata is used when the write operation is to be done regardless of the chunking scheme used in the SDS. Also, as SDwritechunk is written specifically for chunked SDSs and does not have the overhead of the additional functionality supported by the SDwritedata routine, it is much faster than SDwritedata. Note that attempting to use SDwritechunk for writing to a non-chunked data set will return a FAIL (or -1).
The parameter datap must point to an array containing the entire chunk of data. In other words, the size of the array must be the same as the chunk size of the SDS to be written to, or an error condition will result.
There are two FORTRAN-77 versions of this routine: sfwchnk writes numeric data and sfwcchnk writes character data.
SDwritechunk returns either a value of SUCCEED (or 0) or FAIL (or -1). The parameters of SDwritechunk are in Table 3AD. The parameters of SDwritedata are listed in Table 3D on page 30.
TABLE 3AD - SDwritechunk Parameter List
3.11.4 Reading Data from Chunked SDSs: SDreadchunk and SDreaddata
As both SDwritedata and SDwritechunk can be used to write data to a chunked SDS, both SDreaddata and SDreadchunk can be used to read data from a chunked SDS. SDreaddata is discussed in Section 3.5.1 on page 28. The syntax of SDreadchunk is as follows:
C: status = SDreadchunk(sds_id, origin, datap);
FORTRAN: status = sfrchnk(sds_id, origin, datap)
OR status = sfrcchnk(sds_id, origin, datap)
SDreadchunk is used when an entire chunk of data is to be read. SDreaddata is used when the read operation is to be done regardless of the chunking scheme used in the SDS. Also, SDreadchunk is written specifically for chunked SDSs and does not have the overhead of the additional functionality supported by the SDreaddata routine. Therefore, it is much faster than SDreaddata. Note that SDreadchunk will return FAIL (or -1) when an attempt is made to read from a non-chunked data set.
As with SDwritechunk, the parameter origin specifies the coordinates of the chunk to be read, and the parameter datap must point to an array containing enough space for an entire chunk of data. In other words, the size of the array must be the same as or greater than the chunk size of the SDS to be read, or an error condition will result.
There are two FORTRAN-77 versions of this routine: sfrchnk reads numeric data and sfrcchnk reads character data.
SDreadchunk returns either a value of SUCCEED (or 0) or FAIL (or -1). The parameters of SDreadchunk are further described in Table 3AE. The parameters of SDreaddata are listed in Table 3K on page 38.
TABLE 3AE - SDreadchunk Parameter List
3.11.5 Obtaining Information about a Chunked SDS: SDgetchunkinfo
SDgetchunkinfo is used to determine whether an SDS is chunked and how the chunk is defined. The syntax of this routine is as follows:
C: status = SDgetchunkinfo(sds_id, c_def, flag);
FORTRAN: status = sfgichnk(sds_id, dim_length, flag)
Currently, only information about chunk dimensions is retrieved into the corresponding structure element c_def for each type of compression in C, and into the array dim_length in Fortran. No information on compression parameters is available in the structure comp of the union HDF_CHUNK_DEF. For specific information on c_def, refer to Section 3.11.1 on page 62.
The value returned in the parameter flag indicates the data set type (i.e., whether the data set is not chunked, chunked, or chunked and compressed).
If the data set is not chunked, the value of flag will be HDF_NONE (or -1). If the data set is chunked, the value of flag will be HDF_CHUNK (or 0). If the data set is chunked and compressed with either RLE, Skipping Huffman, or GZIP compression algorithm, then the value of flag will be HDF_CHUNK | HDF_COMP (or 1). If the data set is chunked and compressed with NBIT compression, then the value of flag will be HDF_CHUNK | HDF_NBIT (or 2).
If the chunk length for each dimension is not needed, NULL can be passed in as the value of the parameter c_def in C.
SDgetchunkinfo returns either a value of SUCCEED (or 0) or FAIL (or -1). Refer to Table 3AF and Table 3AG for the description of the parameters of both versions.
TABLE 3AF - SDgetchunkinfo Parameter List
TABLE 3AG - sfgichnk Parameter List
EXAMPLE 17. Writing and Reading a Chunked SDS.
This example demonstrates the use of the routines SDsetchunk/sfschnk, SDwritedata/sfwdata, SDwritechunk/sfwchnk, SDgetchunkinfo/sfgichnk, SDreaddata/sfrdata, and SDreadchunk/sfrchnk to create a chunked data set, write data to it, get information about the data set, and read the data back. Note that the Fortran example uses transpose data to reflect the difference between C and Fortran internal storage.
C version
FORTRAN-77 version
[Top] [Prev] [Next]
hdfhelp@ncsa.uiuc.edu
HDF User's Guide - 07/21/98, NCSA HDF
Development Group.